����ժҪ������Ϣ���ݽ����������ĵ��£������ھ������ѧϰ�������ٷ�չ�����У��Ƽ������ڸ�Уѧ����ѧϰ���������ѳ�Ϊһ����������Ȥ���÷�����ʽ������ڿ��ٽ���ѧ�����ۺϳɼ���ѧϰ��Ϊ֮��Ĺ����ȡ��ھ�ѧ��ѧϰ����Ȥ������ͬʱ��ʵ�ֶ�����ͼ��ĸ��Ի���
��������Ϣ���ݽ����������ĵ��£������ھ������ѧϰ�������ٷ�չ�����У��Ƽ������ڸ�Уѧ����ѧϰ���������ѳ�Ϊһ����������Ȥ���÷�����ʽ������ڿ��ٽ���ѧ�����ۺϳɼ���ѧϰ��Ϊ֮��Ĺ����ȡ��ھ�ѧ��ѧϰ����Ȥ������ͬʱ��ʵ�ֶ�����ͼ��ĸ��Ի��Ƽ����Ѿ���Ϊ��У�о�����ѧ������ѧϰ�ķ���֮һ�������������Эͬ���˵�ͼ���Ƽ��㷨��ͨ������Уѧ����ѧϰ��Ϊ�������ݷ���������Эͬ���˵ĸ��ʾ���ģ�ͣ��Ӷ�����ѧ��ѧϰ����Ȥ����ֵ������ʵ����ѧ���Ƽ����Ի�ͼ����Ϣ��ƽ̨�Ĵ����һ������ѧ��ѡ����˸���Ȥ��ͼ�飬�����Ķ���ѧϰ��֪ʶ��չ������У����ѧ�罨�衣
��������о�Ŀǰ���ڶ����Ƽ��㷨��ѧ���γ���������Ȥƫ���е������������˽�Ϊ������о������������ö�ά���Լ�������������ھ���������Эͬ�����㷨�������㷨�Բ�ͬ�û�Ⱥ��ͼ��������ݽ��з�����̽����������Ե�ͼ���Ƽ�������ԣ�����ͼ��ݷ���������
����ͼ������ķ�������ʱ��ͼ��������Ƶļ�ֵȡ��̽��
�������ռ����û�֮��������Բ��봫ͳ��Эͬ�����Ƽ��������ϣ�����˻����û���Ȥ���еĸĽ�Эͬ����ͼ���Ƽ���������Ƽͨ��ʵ����ԣ����������ھ�����ͼ���Ƽ�ϵͳ�Ƽ�����Ŀ��ʵ�ʽ��ĵ���Ŀ�����Ǻϣ��ж�ȷ�ԶԱȴ�ͳ��ʽ�����ߡ�������Ҳ���һ�ֽ�����ƫ�õ�Эͬ�����Ƽ��㷨����ԭ�㷨�����û����ƶȵĻ����ϣ�����û����ƫ�õ����ƶ���������ڣ��Ӷ��õ��Ƽ������
�������еĹ����о����ص㿼���ڶ�Эͬ�������ݵĹ��������о��ϣ������ھ�ѧ������Ȥ����ֵ�������о����١��ڹ����о��У�TewariҲ�����˸�����ҵ���Ȥ�Ƽ�ͼ��Ĺ۵㣬�������һ�ֻ������ݹ��ˣ�Эͬ���˺��������ھ����ϵ�ͼ���Ƽ�ϵͳ��Parvatikarͨ��������Э���Ĺ��˺��������ھ��������������ͼ���Ƽ�����ϡ�������⣬�Ի�ø��õ����ܡ�
����Mathew���������һ�ֻ������ݹ���(CBF)��Э������(CF)���������ھ��������������Ƽ�ϵͳ(BRS)���Բ�����Ч����Ч���Ƽ����������������Эͬ���˵��Ƽ��㷨����������Эͬ���˵ĸ��ʾ���ģ�͵�ѧ����Ȥ�����ھ�������Ƴ�һ�������Ȥ�����Ƽ��ĸ��Ի�ͼ���Ƽ�ϵͳ���Դﵽ��ѧ���Ƽ����Ի�ͼ����Ϣ��Ϊѧ��������Ϣ���ṩ������Ŀ�ġ�����Эͬ���˵��Ƽ��㷨���õ�Эͬ�����㷨��Ϊ���֣������û���Эͬ�����㷨(user-basedcollaborativefiltering)���Լ�������Ʒ��Эͬ�����㷨(item-basedcollaborativefiltering)��
������ϵͳ��Ŀ������ѧ�����и��Ի�ͼ���Ƽ������û����û���Эͬ�����㷨�������û�ƫ�ö�ά�����֡�������Ȥ�������������Ƽ��б�����ó�ȷ�ʺ��ٻ�����ߵĴ�Ȩ������Ȥ�������������ά�����ֶ�ά��������ָ����Эͬ�����Ƽ��Ļ��������о���ȡ����ѧ����Ŀ�ɼ����ղ��鼮���鼮�Ķ��ٶȡ��鼮���������۵���Ϊ�����ݸ���ѧϰ��Ϊ��Ӧ���û���Ȥ���������м�Ȩ�����������һ����Ԥ�������û�ƫ�ö�ά����ģ�ͣ����û��б�����Ʒ�б���Ϊγ�ȳ߱꣬�ó��û�����Ʒ��ƫ��ֵ��
������Ȥ���������Ȥ���������ָ������������õ��û�ϲ�úõ��û���Ȥƫ�������������û�֮������ƶȡ��ڳ��õ�ŷ����¾��롢Ƥ��ѷ���ϵ����Cosine���ƶȡ�Tanimotoϵ������Ȥ�����㷨�У����о�����Cosine���ƶȷ����������㷺Ӧ���ڼ����ĵ����ݵ����ƶȣ�����xi��yi�ֱ����x�û���y�û����鼮i�����֣���������������ֵԽС�����ƶ�Խ�ߡ�
���������Ƽ��б������Ƽ��б�����Ҫ���Ծ���Apriori�㷨�ھ��������ȡ�������û���������Ʒ�����ݻ����û���CF˼�룬�����û�û��ƫ��ֵ�ĺ�ѡ����ٸ��ݹؼ���Ƶ��ɸѡ���˵�������С֧�ֶȵ�Ƶ����������ȡ��ǿ�����Ĺ����Ƽ��б���ץȡ��Ӧ�鼮���ݲ������Ƽ���
������������Эͬ���˵�ͼ���Ƽ�ϵͳĿǰ����Уͼ�����������Դ������Ϊͼ����Դ����ṩ��Ϣ�������ļ���ѯ���ܣ�ȱ��������Ե���Ϣ�Ƽ����ܡ����о�Ϊ����û���ȡĿ���鼮��Ч�ʣ���һ������ѧ�������Ķ���ѧϰ��֪ʶ��չ��Ϊ�˽���Уѧ����ѡ�γ̽���ȷ��λ��������ѧ�����ڿγ̵����ۣ�ͬʱ��ϻ�������ѧ����������ݹ������뱾����Ȥһ�µ��Ƽ��鼮����Эͬ���˵��Ƽ��㷨�����Ϲ�������˿��ӻ��ĸ��Ի�ͼ���Ƽ�ϵͳ��
������ϵͳ������ѧ��ѧϰ��Ϊ��Ԥ��������ַ��ӻ�������Ϊѧ����ȡͼ����Ϣ����Ҫ;�����ص㣬���������ھ�����ȡ��ѧ���������ʷ�������鼮�����ݽ�ϣ�ʹ��Python���Զ����ݽ���Ԥ������������ʧ��������ƫ��ֵ��������Ȥ����ֵ�����ݵĹ����Է�����ץȡѧ�����Ի��Ƽ��鼮�б����ɴ����Эͬ�����Ƽ��Ĺ��̣�������Ӧͼ����Ϣ��ϵͳƽ̨��չ�֡�
����ѧ��ѧϰ��Ϊ��������Ȥ��������Ը�Уѧ��ѧϰ��Ϊ����Ϊ��������ѧ������γ̳ɼ���ѡ�ογ̳ɼ����з�������ȡѧ��������������ѧ�ƣ�����ѧ��ѧ��Ȩֵ���ص��Ȩ������Эͬ����ͶƱģ�ͣ���ʵ��ѧ����ȡ�����̵ĸ��Ի�ͼ���Ƽ�����Σ���ѧ����ѡ�η�����ѧ�����Ի�ѡ�γ��������ݽ��з���������ѧ����֪ʶ����ͼ�ף���ѧ���ص��������Ϊ���ġ�רҵ����ȤΪ�Աȳ߱꣬�ﵽ�ַ�����ж�ά����Ȥ������Ŀ�ġ�
����ͬʱϵͳ�����û��ṩ�Ķ���Ȥ������ѡ������Ȥ����ͼ��ѡ�������֣����Ķ���Ȥ����Ϣ��֪ʶ����ͼ��Ͻ��г���ɸѡ��������ά���ݵ�������ϵ�����Эͬ���˵ĸ��ʾ���ģ�ͣ�����ʵ��ѧ����Ȥ����ֵ�ij������㡣ͼ����Ϣ��̬��ȡ������Ԥ������ͼ����Ϣ�Ķ�̬��ȡ�ϣ�ʹ�û���Python��BeautifulSoup������漼�������ŵ�ͼ����Ϣ��վ�����ݽ��ж�̬�ھ�ͼ����������Լ�ÿ����ѡͼ�鲿�ֽ��б�ǩҳ�Ķ�ʱ��̬��ȡ�����xpath��ȡ�����г��ֵIJ�������ȡ������ü��϶�λӳ��ķ����������Զ���xpathʵ�ֶ���ҳ������ץȡ��
����ͨ����ѧ����Ȥ����ֵ�ķ�������ץȡ��ͼ�����ݽ���������ϴ�����Ⱦ�����������ͼ��ؼ��ʽ��л�ȡ���ų�ѧ�ƹ����̶ȵ͡��ɿ��Ե��Լ��ظ��ھ����������ݡ�������Ȩ�ر�ɸѡ���ؼ������ݣ����������ɸѡ�����ݵĿɿ���������ȡ���ƫ��ϴ�����ݽ����ų���������ʧ�����ݡ�����ƫ��ֵ��Ϊ��������ͳ�ơ���Ȥָ��ļ��㡢�Լ����ݹ����Է����춨���ݻ�����
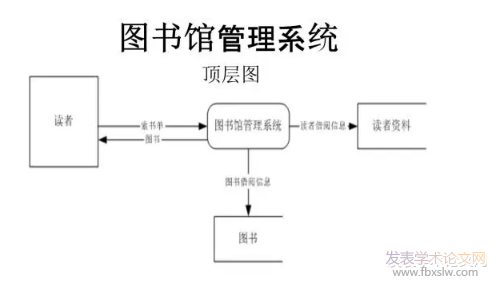
������������ϴͼ�����ݵ���Ϣ�洢��ȷ������ת������������һ����ȷ�ԡ���������Эͬ���˵�ͼ���Ƽ�ϵͳ��ϵͳ�Ŀ��ӻ�ƽ̨��MVCģʽ���й������ͻ�����ͼ���Ƽ�ϵͳʹ��Vue��ܡ�Ӧ�ò����ȡSSM��ܽ��п������ڶ�������ʵ���ⲿͼ����վ�ӿڵĻ�ȡ�����ӣ�Ϊ�ھ�ѧ����Ȥ�����ԣ���ʵʱ�����鼮����ʵ���˶�̬��ȡ�������ȵ㡢�ۺ��Եش�����Уѧ����������ѧϰ����Ȥ��
�����������������ģ�顢���ݷ���ģ����ϵͳչʾģ�������֡�����ģ�����ģ�飬�����û������Ⱥ���Ȥ���ƶȼ��㷽������k�ż��������û���ͼ�����ݰ���ƫ�þ���Ȩ��ֵ��С���л�ȡ����ȡ��ά�ȵ�ͼ������Դ;���ݷ���ģ�飬�����ݲ��н�ѧ����ѧϰ��Ϊ���ݽ��д���������ͨ��Эͬ�����㷨�����ѧ��ѧϰ��Ҫ��ȡͼ��������ԡ�
�������ϵͳչʾģ�飬���ھ���Ԥ������ϴ��ͼ����Ϣ�����ѧ������Ȥ����ؼ���ɸѡ��������ϵͳ�д洢�ĸ��Ի��Ƽ��鼮���������ۺ�ҳ�潫ѧ����Ϊ�����ε��ۺϳɼ������������Ȥ������ͼ�εķ�ʽչ�֣������û�����Ѹ�١�ֱ�۵ز鿴ͼ��������Ϣ����ϵͳ�ڿͻ���ʹ��Vue��ܽ�����ͼ���濪���������������ͼ���Ƽ����ͨ��API�ӿ��ڸ����Ƽ�ҳ����ж�ȡ��չʾ������ϵͳ����ɷֲ�ʽ���𡢶���̡����ؾ����ͼ���Ƽ�ϵͳ�Ĺ�������ͨ��
�����ܽ�
�����Լ���ѧ������ѧϰ�����Ƽ�ΪĿ�꣬���Ľ��ѧ���Ķ���Ȥ�����������Эͬ�������������ĸ��Ի�ͼ���Ƽ�ϵͳ��������Ȥ����ֵ�����������棬�������Ի�Эͬ�����Ƽ��㷨Ӧ�õ�ѧ��ͼ���Ƽ�ƽ̨�Ľ����С����������ѧ��֮���鼮�Ļ�ȡЧ������Ϣ����������ѧ�����������Ķ�����Ҫ�Բ�������Ը��Ի��鼮�Ƽ������Ӷ�����ѧ�����Ķ�ѧϰ֪ʶ����Ȥ����һ���о��У�����һ����ǿ���Уͼ���������Դ������ϵ���������ѧУͼ��ݶ���ѧ����רҵͼ�������Լ�ѧ����ͼ��ݽ����鼮�ļ�¼����һ�����Ʊ��ļ��㷽�������ṩ�����Ի���ͼ����Ƽ�ƽ̨��
�������ߣ�������;���t�B;������;������

ת����ע�����Է���ѧ����������http://www.fbxslw.com/jjlw/26829.html