本文摘要:摘 要:资源匮乏语言语音信息检索研究比汉语、英语等大语言进展缓慢,需要大量预处理工作。神经网络模型在低资源环境下的高效建模能力给低资源语言信息处理工作带来便利。文中以维哈等低资源语言为基础,通过一系列预处理过程获得了这些语言的语音及文本资源,再利用高
摘 要:资源匮乏语言语音信息检索研究比汉语、英语等大语言进展缓慢,需要大量预处理工作。神经网络模型在低资源环境下的高效建模能力给低资源语言信息处理工作带来便利。文中以维⁃哈等低资源语言为基础,通过一系列预处理过程获得了这些语言的语音及文本资源,再利用高斯混合隐马尔可夫模型GMM⁃HMM、深度神经网络隐马尔可夫模型DNN⁃HMM等完成了关键词检索实验。实验结果表明,三音素下的 DNN ⁃HMM 模型比 GMM ⁃HMM 模型检索性能要好。维吾尔语的ATWV达到了0.368,MTWV达到了0.491,检索结果准确率达到了89.36%;哈萨克语的ATWV达到了0.382,MTWV达到了0.421,检索结果准确率达到了 82.15%。
关键词:语音关键词检索;维吾尔语;哈萨克语;深度神经网络;检索流程;声学模型
0 引 言
资源匮乏的语言语音信息检索研究进展缓慢,缺乏资源,需要大量的预处理工作以及相关的细致研究。虽然维⁃哈(维吾尔⁃哈萨克)语言的 ASR 系统研究有了一些成果[1⁃2],但是在关键词检索方面缺乏深入研究工作。在移动终端以及多媒体信息爆炸性增长的年代,多语言语音信息的检索研究在社会发展、网络安全、舆情分析等多个领域有很重要的现实意义,将进一步推进低资源语言语音检索的研究。本文主要在大词汇量语音识别(Large VocabularyContinuous Speech Recognition,LVCSR)系统的基础上进行维⁃哈语言语音关键词检索,首先对维⁃哈语语音各种声学单元分别建模,在此基础上进行维⁃哈语音关键词检索。
大词汇量语音关键词检索是在语音识别产生的网格 lattice 上进行关键词捕捉。由识别和索引两部分组成[3],关键词检索的方法通常都是用关键词的模板在连续语音流中进行匹配查找,比如 DTW(DynamicTime Warping)方法和 DTW 的不同变体等。表示关键词模板的方法有 GMM 模型[4⁃5]、HMM 模型[6]、神经网络等,它们对各种特征进行匹配,这些特征包括语音的频谱、MFCC(Mel Frequency Cepstrum Coefficient)、线性预测系数(Linear Prediction Coefficient,LPC)[7]等。但是这种用关键词模板匹配的方法适用于较小的数据量进行关键词检索,并且关键词的不同模板在表示上有很大的差别。
影响检索的因素有噪声、信道不匹配、标记有误等因素[8]。随着大词汇量连续语音识别准确率和效率的不断提高,可以在连续语音识别的基础上进行语音关键词检索,通常比 DTW 模板匹配的结果好,所以连续语音关键词检索具有很好的应用价值[9]。关 键 词 检 索 系 统 性 能 的 评 价 指 标 是 加 权 项 值(Term ⁃weighted Value,TWV),衡量系统对伪命中和误报的代价的分配[10⁃11]。本文使用两种不同的评价指标:ATWV(Actual Term⁃weighted Value,实际项加权值),即通过预先指定的决策阈值获得的TWV;MTWV(MaximumTerm⁃weighted Value,最大项加权值),它是在判决阈值的最佳设置下获得的 TWV[12]。汉语、英语等大语言相关研究很多,如汉语语音关键词检索,在文献[13]里通过神经网络模型研究语音检索达到的准确率是80.76%。由于在实际环境中,噪声、个性化、情绪等众多因素的影响,检测正确率还会大幅降低。
1 系统总体框架
本文的关键词检索是在 LVCSR 基础上实现的。为了提高可靠性,在 LVCSR 输出端捕捉 lattice 输出,并在此基础上进行检索。维⁃哈语音关键词检索的总体流程是:首先对维⁃哈语音分别进行识别,产生相应的 lattice,再进行语音关键词检索。其实 lattice 只是在语音识别的过程中产生的中间结果,是由每条测试集句子解码并联起来的一个庞大的网格,网格里面包含测试集每条句子的每个候选词,网格以加权有限状态转换器形式存在,检索时也需要将检索的关键词转换成加权有限状态转换器的形式在网格上进行索引,进而在 lattice 进行语音关键词检索。
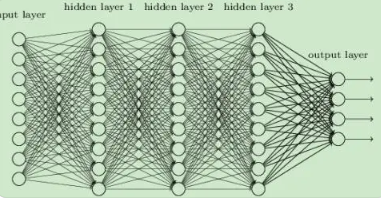
本文建立 GMM,DNN,HMM 等各种 LVCSR 系统模型,选择各种声学模型进行比较,使用的模型。GMM 和 DNN 都在拟合同一个观测序列的概率分布,然后作为 HMM 的观测状态概率矩阵,从 HMM指向 GMM 或 DNN 的箭头是指 HMM 的某个状态的观测概率由某一个 GMM 或 DNN 的某一个输出节点决定;两者最主要的区别是利用 DNN 代替了 GMM 实现了状态概率的输出;后验概率可以看作是有监督学习,根据观测值求状态值,而 DNN 是根据观测值逆向传播的过程,属于有监督学习;另外,经过 softmax 输出就能得到后验概率。
HMM 的观测概率由 GMM 生成。一个状态 X 由一个 GMM 表征,同时相邻的 GMM 之间没有很强的相关性;GMM 模型输出的似然概率为 P ( Y | X ),这个似然概率就是 HMM 所需要的观测概率。在图 3 中,HMM 的观测概率由 DNN 生成的后验概率 P ( X |Y )经贝叶斯公式转换得到。DNN 一个输出节点对应一个状态,为了考虑上下文相关信息,通常送入DNN 的是 2n + 1 帧;DNN 作为判别模型,是直接对给定的观测序列 Y 后状态的分布进行建模,也是监督学习,输 出 的 后 验 概 率 P ( X |Y ) 需 要 转 换 为 似 然 概 率P ( Y | X )。相同点,HMM 的状态初始概率和状态转移概率都不变,HMM 仍然是对时序进行建模。
2 实验数据
准备实验中,维吾尔语语音关键词检索使用的语音语料包括:训练集有 7 600 条音频和文本句子,验证集有400 条音频和文本句子,测试集有 1 468 条音频和文本句子。哈语语音关键词检索使用的语音语料包括:训练集有 34 000 条音频和文本句子,验证集有 1 000 条音频和文本句子,测试集有 2 000 条音频和文本句子。
3 实验结果及分析
维吾尔语语音识别词错误率,哈萨克语语音识别词错误率分别。在录哈语语音数据时,里面存在的一些年份、数字等在字典里没有对应的发音音素串,都映射成了集外词。维语使用了公开的语料库 thuyg20,字典基本覆盖了数据集所有的单词、年份、数字等发音。所以维语数据集不但小,而且识别的效果较好;哈语的数据集大,反而识别效果较差些。为了更直观地表示维⁃哈语语音在不同的声学模型中识别词错率的情况,本文采用折线图表示。通过折线图,观察不同的声学模型,发现维吾尔语 DNN ⁃HMM 比 mono识别率提升了 28.54%;哈萨克语 DNN⁃HMM 比 mono 识别率提升了 27.99%。
3.1 基于 GMM⁃HMM 声学模型
维语实际总的关键词词数为 1 602,使用 F4DE 获得。分别使用单音素(mono)模型、三音素(tri1)模型、LDA +MLLT 的三音素模型(tri2b)、SAT 的三音素模型(tri3b)、quick 训练(tri4b)的 GMM⁃HMM 模型,做语音关键词检索,检索出正确关键词数、总的关键词数、虚警关键词词数,根据关键词检出系统性能评价指标可得准确率、召回率、虚警率。
哈语实际总的关键词词数为 1 303,使用 F4DE 获得。分别使用单音素(mono)模型、三音素(tri1)模型、LDA +MLLT 的三音素模型(tri2b)、SAT 的三音素模型(tri3b)、quick 训练(tri4b)的 GMM⁃HMM 模型,做语音关键词检索,检索出正确关键词数、总的关键词数、虚警关键词词数,根据关键词检出系统性能评价指标可得准确率、召回率、虚警率。
3.2 基于 DNN⁃HMM 声学模型
使用三音素的 DNN⁃HMM 模型做语音关键词检索。维吾尔语实际总的关键词词数为 1 602,用 F4DE 获得,检出 正 确 的 关 键 词 数 为 1 444,检 索 到 的 关 键 词 数为 1 616,虚警数为 103,由关键词检索的评价公式可得 ,准 确 率 为 89.36%,召 回 率 为 90.14%,虚 警 率 为6.43%;哈 语 实 际 总 的 关 键 词 总 数 为 1 303,用 F4DE获得,正确识别的关键词数为 1 118,检出的关键词数为 1 361,虚警数为 192,根据关键词检出系统性能评价指标可得,准确率为 82.15%,召回率为 85.80%,虚警率为 14.74%。
通过实验对比发现,在不同的声学模型上,维语和哈语的关键词检出的查准率、召回率、虚警率都有所不同,但是在 DNN⁃HMM 模型上的性能最佳,维吾尔语达到了 89.36%,相比单音素而言提升 33.11%,哈语达到82.15%,相比单音素而言提升 52.06%。相比于高斯混合模型而言,深度神经网络更能拟合数据的分布,进而提高关键词检出的准确率。
4 结 语
本文虽然在 kaldi中搭建了完整的语音关键词检索系统,也做了多次实验,但是,哈萨克语的语音识别词错误率较高,对关键词检出的准确率有较大的影响,维吾尔语的语音识别的词错误率相对于哈萨克语来说较低。通过实验数据也可以看出,维吾尔语的关键词检出的准确率较高,下一步的工作就是尝试一些不同的方法完善发音字典和声学模型,提高哈萨克语识别的准确率,进而提高哈萨克语的语音关键词检出的准确率。
参 考 文 献:
[1] 沙尔旦尔·帕尔哈提,米吉提·阿不里米提,艾斯卡尔·艾木都拉 . 基于词干单元的维⁃哈语文本关键词提取研究[J]. 计算机工程与科学,2020,42(1):131⁃137.
[2] 孙晓杰 .基于 N⁃gram 模型的哈萨克语语音识别及处理技术研究[J].信息记录材料,2018,19(9):97⁃99.
[3] 李娜,葛万成 . 语音关键词识别系统的模型训练及性能评价[J].信息通信,2020(3):8⁃10.
[4] GUPTA M,BHARTI S S,AGARWAL S. Gender⁃based speakerrecognition from speech signals using GMM model [J]. Modernphysics letters B,2019,33(35):1⁃23.
[5] LANNE M,LUOTO J. GMM estimation of non⁃Gaussian struc⁃tural vector autoregression [J]. Journal of business & economicstatistics,2021,39(1):69⁃81.
作者:张伟涛,米吉提·阿不里米提,郑 方,艾斯卡尔·艾木都拉

转载请注明来自发表学术论文网:http://www.fbxslw.com/wslw/30259.html