本文摘要:摘要:以未来战场无人地空协同作战为需求牵引,面对军事领域实战场景匮乏、训练数据不足的实际问题,聚焦仿真环境下的深度强化学习方法,实现地空协同作战仿真中多智能体决策模型。在飞腾CPU和昆仑K200硬件平台与麒麟V10操作系统环境下搭建虚拟仿真环境,设置仿真环境
摘要:以未来战场无人地空协同作战为需求牵引,面对军事领域实战场景匮乏、训练数据不足的实际问题,聚焦仿真环境下的深度强化学习方法,实现地空协同作战仿真中多智能体决策模型。在飞腾CPU和昆仑K200硬件平台与麒麟V10操作系统环境下搭建虚拟仿真环境,设置仿真环境状态表征、各智能体动作空间及奖励机制,构建基于深度确定性策略梯度算法的多智能体模型(MADDPG),通过仿真实验验证采用MADDPG算法能够使奖励值在地空协同作战仿真场景中逐渐收敛,从而证明该模型应用于地空协同作战的决策有效性。
关键词:地空协同作战;强化学习;基于深度确定性策略梯度算法的多智能体模型;国产化环境
引言
随着未来战争环境愈发复杂多变,具有强隐蔽性、高伴随性、不受时空因素制约无人作战装备的重要性日益凸显[1],甚至将颠覆传统战争理念。在无人化装备基础上,为提升作战效能提出的协同作战概念也引起了广泛关注。不论是有人-无人协同,还是无人-无人协同,通过态势共享、统一决策,形成功能完备、优势互补的有机整体,达到1+1>2的效果。地空协同作战是未来协同作战的重要形式,无人机将是坦克在侦察、火力等方面的强力补充,二者联合作战可实现作战集群整体效能最大化[2]。
得益于近年来人工智能技术的飞速发展,单一无人装备的控制方式逐步由远程遥控向自主控制转变,已初步具备感知、分析、决策和执行的能力,但协同作战能力仍有限。接近实际应用场景的无人地空联合作战更由于可变因素众多、环境复杂性高而呈现出异常艰难的特点。
另一方面,数据稀缺性很大程度上限制着以传统算法进行的无人协同作战研究,主要体现在无法通过收集真实的战场数据调教智控算法。强化学习的兴起为无人协同作战提供了另外一种研究思路,以作战单元为智能体,通过其自学习优化策略,在无训练数据的条件下实现复杂战场环境中的地空力量协同配合。本文针对实战环境稀缺、作战数据积累不足等实际问题,聚焦于仿真环境中的强化学习方法。同时考虑到自主可控需求,在国产化飞腾CPU和昆仑K200硬件平台与麒麟V10操作系统环境上搭建了虚拟仿真环境,构建了一种地空协同作战场景下的基于深度确定性策略梯度算法的决策模型,通过智能体与环境交互自学习,以实现地面装备、无人机等智能体的相互协同与配合攻敌。
1相关研究
决策模型是作战仿真模拟的“大脑”,一般可分为基于规则、基于深度学习和基于强化学习的三种方法[3]。基于规则的决策模型是对专家经验建模,形成具有泛化能力的状态机,驱动仿真对象的行为,其优势是可以充分利用先验知识,但策略空间有限,适用于领域知识完备的军事博弈对抗;基于深度学习的决策模型是通过学习历史对抗数据生成决策神经网络,具有较高的泛化性,但模型依赖于海量数据积累且可解释性差;基于强化学习的决策模型是利用智能体不断试错以学得决策网络。基于强化学习的方法和基于深度学习的方法类似,虽然都存在可解释性差的问题,但其优势是不需要依赖数据积累,因此格外适合军事领域缺乏训练数据积累的场景。
1.1深度强化学习
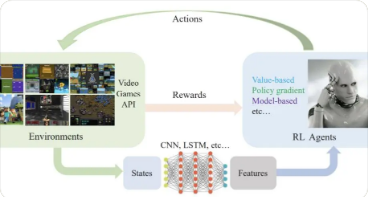
强化学习(RL)的要素包括环境、智能体、值函数和策略函数,其核心思想是通过最大化智能体从环境中获得的奖励值,以学习到完成目标的最优策略。随着深度Q网络(DQN)[4]的提出而兴起的深度强化学习(DRL)是强化学习和深度学习的结合。DQN创新性地使用深度神经网络作为近似表示值函数的方式,以处理视觉图像为输入的任务。利用深度神经网络,一可以更高效地表征环境状态,二可以使奖励函数训练拟合更稳定,三可以提高算法的泛化能力使之适用于不同任务。
DRL算法大致可分为基于值函数的DRL、基于策略梯度的DRL和基于搜索与监督的DRL三类。以DQN为代表的基于值函数的DRL算法通过更新值函数Q来学习行动策略,但只适用于离散动作空间。在真实场景中,如自动驾驶、无人机控制等,往往需要输出连续的动作更精确地操控智能体。
Lillicrap等[5]基于策略梯度优化方法改造DQN,提出基于行动者-评论家(AC)框架的深度确定性策略梯度(DDPG)算法,可用于解决连续动作空间上的DRL问题。基于搜索与监督的DRL是将监督学习和搜索策略相结合,常应用于游戏博弈中,AlphaGo围棋算法[6]中利用蒙特卡洛搜索树结合策略网络以及值网络的方法,就是这种DRL策略的典型实践。
1.2多智能体强化学习
在解决真实场景复杂决策问题过程中,往往涉及到多个智能体间的协作配合,因此仅考虑单一智能体的决策模型问题解决能力十分有限,多智能体深度强化学习(MADRL)成为强化学习领域研究的重点和难点。MADRL问题按智能体协作类型可分为完全合作、完全竞争和混合环境。Hernandez-Leal等[7]将MADRL研究分为以下4类内容:
1)行为分析。把DRL算法直接应用与多智能体环境中,每个智能体独立学习行为策略并将其他智能体看作环境的一部分[8],适用于完全合作、完全竞争和混合环境,但容易出现非平稳性问题。2)通信学习。着重探索智能体间共享信息的方式,如直接消息通讯或共享内存,可用于处理完全合作和混合环境问题。
3)协作学习。在智能体间无通信的环境下,将多智能体学习、强化学习的思想扩展到MADRL领域,该类型工作仍然是多智能体学习的主流方向。例如将DDPG算法扩展到多智能体环境的多智能体深度确定性策略梯度算法(MADDPG)[9]。该类型算法实验环境包括完全合作、完全竞争和混合环境。4)智能体建模。通过对智能体建模,加强智能体间合作、推断隐藏目标以及解释其他智能体的学习行为。这类算法通常应用于完全竞争和混合环境。
1.3军事应用
强化学习侧重学习解决问题的策略,因此被认为是通向人工智能的重要途径。目前强化学习已在参数调优[10]、机器人控制[11]、游戏博弈[4,6,12]、自动驾驶[13]等场景中得到了广泛应用。随着技术逐步成熟,强化学习在军事领域也得到了更多的关注。军事博弈与游戏博弈有着高度相似性,因此AlphaGo、AlphaStar的成功引发了强化学习在指挥决策[14]、作战任务规划[15]中应用的探讨。
仿真作战方面,李航等[3]构建了适用于强化学习的军事智能博弈对抗系统框架;徐志雄等[16-17]将基于DoubleBP神经网络的分层强化学习方法、基于MMSarsa的强化学习方法应用于坦克对战仿真中;卢锐轩等[18]设计并实验了基于强化学习的1V1空战仿真;黄晓冬等[19]将DQN算法应用到海战场船舶路径规划仿真中。作为军事领域战术优化、决策辅助的重要手段,目前基于强化学习的仿真作战研究还存在着想定单一、仿真环境设置简单、未充分考虑实际协同作战需求的不足,距离实战应用仍有一定的距离。
2基于MADDPG的地空协同作战模型构建
地空协同作战是典型的混合环境下多智能体学习问题,其中对智能体的控制是一个连续过程,DDPG算法以及MADDPG算法可实现对各智能体的连续操控。另外,多智能体MADDPG算法全局化学习策略相较每个智能体单独使用DDPG学习能获得更平稳地训练过程。
因此,本文基于MADDPG算法构建地空协同作战模型,在不需要训练样本的前提下,依托作战仿真环境对多智能体进行训练。多智能体深度确定性策略梯度(MADDPG)算法[9]通过改造DDPG算法,使其适用于多智能体环境。MADDPG算法的核心思路是在训练阶段使用观察全局的Critic网络获取其他智能体的策略,而推理阶段仅使用有局部观测的Actor网络采取行动,即中心化训练和非中心化执行。这种结构一是使智能体学得更加全局的策略,二是可以缓解由于智能体分别优化策略而导致的环境不稳定问题。
3实验设计及结果
基于国产化软硬件环境,设计红蓝双方对抗想定以验证地空协同作战中MADDPG算法决策的有效性。
3.1实验环境搭建
实验环境的搭建分为硬件实验环境和软件仿真环境两个部分。硬件实验环境设施采用国产化自主可控器件,以应对目前军事领域对国产化要求;软件仿真环境同样采用国产化的深度学习框架与国产仿真推演平台。
3.1.1实验硬件环境
实验硬件环境为一台可插8块国产昆仑K200高性能计算卡和国产飞腾CPU组成的服务器,运行麒麟V10(SP1)操作系统,封装有飞桨国产深度学习框架。整机采用2U机架式,基于国产飞腾S2500设计,具有128个处理器核心,采用ARMV8架构,内存为64GBDDR4ECCRDIMM,硬盘采用240GB数据中心级SSD,支持8块3.5英寸/2.5英寸SATA/SAS6Gb/s热插拔磁盘,3个PCIE3.0×16和3个PCIE3.0×8插槽。昆仑K200高性能计算卡采用XPU架构,HBM内存达到16GB,单块计算卡在全精度浮点数情况下能够提供16TOPS、在半精度浮点数情况下能够提供64TOPS、在8位整型情况下能够提供256TOPS的峰值算力,HBM访问宽带为512GB/s.硬件环境采用PCIE插槽的方式,昆仑K200高性能计算卡通过PCIE与飞腾CPU进行通信。
3.1.2软件仿真环境
软件运行环境基于麒麟V10系统搭建,分为仿真环境和决策模型两部分。仿真环境采用墨子仿真推演平台,包括可视化界面以及与模型交互的数据接口,决策模型基于飞桨深度学习框架实现MADDPG算法。仿真环境和决策模型之间通过数据接口进行交互,实现模型对仿真环境中智能体的驱动以及仿真环境状态、行动奖励对模型的反馈。
3.2仿真环境
构建地空协同作战场景下的仿真作战任务,红蓝双方兵力设置分别为红方坦克2辆,无人机1架;蓝方坦克1辆,地空导弹3排。其中,地空导弹仅具有对空击打能力,固定位置无法移动。无人机具有侦察功能,并携带反坦克导弹。蓝方坦克攻击范围大于红方坦克。任务以红方击毁蓝方坦克为胜利,以红方所有坦克、无人机被摧毁或时间耗尽为失败。分别设定红蓝双方各智能体的奖励机制。
对红方坦克,击毁蓝方坦克记100分,击中但未击毁时得分与蓝方坦克战损值呈正比;击毁蓝方地空导弹记50分,击中但未击毁时得分与导弹战损值呈正比。红方坦克被击毁记-100分,被击中但未被击毁得分与战损值呈反比。红方无人机被击毁记-50分,被击中但未被击毁得分与战损值呈反比。对蓝方坦克来说,击毁红方坦克记100分,击中但未击毁时得分与红方坦克战损值呈正比;被击毁记-100分,被击中但未被击毁得分与战损值呈反比。蓝方地空导弹击中红方无人机记50分,被击毁记-50分,被击中但未被击毁得分与战损值呈反比。
3.3参数配置
本文实验共训练20000轮,每轮训练以红蓝一方胜利或达到单轮最大决策步数结束。每轮最大决策步数为30步,仿真时间每120s进行一步决策,在仿真平台可视化推演速度设置为30倍加速,即每轮训练时间上限为实际时间2min,仿真时间60min.一轮训练结束后,计算双方得分情况,初始化双方得分,进入下一轮学习。MADDPG算法中学习率lr=0.001,折扣因子γ=0.95,更新系数τ=0.01.
4结束语
本文研究了仿真环境下地空协同作战决策模型设计与应用,分析了地空协同作战仿真研究的重点和难点,针对缺乏训练数据的问题聚焦强化学习方法,针对坦克、无人机连续控制问题选用深度确定性策略梯度算法,针对多智能体协同问题最终确定使用MADDPG算法作为地空协同作战决策模型。在国产化软硬件环境下,搭建了地空协同作战仿真实验场景并通过模型训练达到奖励值收敛,从而验证了MADDPG算法在地空协同作战仿真场景下决策的有效性。
多智能体协同作战研究作为军事博弈与人工智能的交叉领域,目前还处于起步阶段,未来将在以下方向继续探索:1)当前仅验证在单一场景下决策模型有效性,可进一步提高模型泛化能力使其适用于多种场景。2)为简化计算过程,目前仅选取部分有代表性的参数描述状态空间与动作空间,存在与真实世界拟合度低的问题,可进一步优化仿真环境状态空间与智能体动作空间的表征。3)强化学习虽然具有无需训练数据等优势,但可解释性差且无法利用专家经验,并且智能体行为存在小范围内抖动的问题,因此可展开强化学习与决策树等方法相结合的仿真决策模型探索。
参考文献(References)
[1]孟红,朱森地面无人系统的发展及未来趋势[J].兵工学报,2014,35(增刊1):17.MENGH,ZHUS.Thedevelopmentandfuturetrendsofunmannedgroundsystems[J].ActaArmamentarii,2014,35(S1):17.(nChinese)
[2]张宇,张琰,邱绵浩,等地空无人平台协同作战应用研究[J].火力与指挥控制,2021,46(5):1,11.ZHANGY,ZHANGY,QIUMH,etal.Researchonthegroundairunmannedplatformcooperativecombatapplication[J].FireControl&CommandControl,2021,46(5):1,11(inChinese)
[3]李航,刘代金,刘禹军事智能博弈对抗系统设计框架研究[J].火力与指挥控制,2020,45(9):116121.LIH,LIUDJ,LIUY.Architecturedesignresearchofmilitaryintelligentwargamesystem[J].FireControl&CommandControl,2020,45(9):116121.(inChinese)[4]MNIHV,KAVUKCUOGLUK,SILVERD,etal.PlayingAtariwithdeepreinforcementlearning[J/OL].ComputerScience,2013.arXivpreprintarXiv:1312.5602.
作者:李理,李旭光,郭凯杰,史超,陈昭文

转载请注明来自发表学术论文网:http://www.fbxslw.com/dzlw/29784.html