本文摘要:摘要:基于RNA-Seq的转录组测序数据特征维度较高,使用传统生信方法寻找表型相关基因需要大量计算资源,且差异分析所得候选基因范围较大,进一步筛选依赖已有的先验知识。针对这一问题,本文提出了融合遗传算法和XGBoost的转录组分析方法GA-XGBoost,通过融入机器学习
摘要:基于RNA-Seq的转录组测序数据特征维度较高,使用传统生信方法寻找表型相关基因需要大量计算资源,且差异分析所得候选基因范围较大,进一步筛选依赖已有的先验知识。针对这一问题,本文提出了融合遗传算法和XGBoost的转录组分析方法——GA-XGBoost,通过融入机器学习算法缩小了后续分析的候选基因范围。在一组高质量玉米数据集上对基因-百粒重性状的关联进行了对比实验和后续分析,结果显示,相比于分别使用全体基因和差异表达基因直接训练XGBoost模型,所提方法得到的候选基因训练的XGBoost模型在玉米百粒重的预测结果上具有最小的MSE;相比于差异表达分析结果的1542个差异表达基因,GA-XGBoost方法最终将候选基因范围减小至48个,范围缩小了31倍,表明所提方法能够有效提升对转录组数据的分析能力和效率。
关键词:遗传算法;XGBoost;机器学习;玉米;转录组分析
引言
转录组分析是一种快速有效的基因组调查、大规模功能基因和分子标记鉴定的方法[1]。相较于基因芯片等方法,基于RNAseq的方法不依赖基因的先验知识,能够覆盖更大的转录组范围,具有更高的分辨率并且测序成本更低[2]。已有很多学者针对RNA-Seq测序数据进行了研究[3,4],其中不乏使用机器学习方法进行研究的方法[5,6]。通过RNA-Seq得到的转录组测序数据具有样本量较少(几十或者几百个)、基因数极高(通常有上万个基因)的特点。数据高维的特点导致对其进行分析需要更大的计算资源和时间;同时,传统的统计方法往往也由于数据维度过高而失效。
因此,对数据进行降维,寻找能够表示其特征空间的最优子集成为了研究人员需要解决的问题。常见的转录组分析方法主要可以分为两类。一类为根据已知的生物学领域知识和统计知识对数据进行处理筛选出相对低维的特征空间进行后续研究,例如差异表达分析。此类方法[7,8]能够较快速的获得特征子空间,但是无法保证子空间能够保留原始空间的全部信息,从而可能导致最终的效果不尽如意。第二类方法结合机器学习算法,从样本的基因全集中选择若干个基因作为特征构建学习器,并根据学习器的性能和基因在学习器中的重要性(如特征权重)筛选候选基因[5]。
此类方法使用学习器的性能作为评判标准,虽然能够获得比较优秀的特征子集,但是只是针对单一特征进行评价,没有考虑到基因之间的相互作用。而基因间的相互作用也会导致表型的差异,如此选出的特征子集往往不是最优子集。遗传算法(GeneticAlgorithm,GA)是一个在全局层面对问题寻找最优解的算法,借鉴了自然界中的物种进化的规律,最早由J.Holland于1975年在其专著《自然界和人工系统的适应性》[9]中发表。
遗传算法每次迭代保留一组候选解,通过模仿生物繁殖的过程产生新的候选解集。使用遗传算法搜索最优特征子空间的优势在于它不需要事先考虑相关的领域知识,并且由于每次迭代都是针对一个种群进行整体评价,因此能够考虑特征间的相互作用。目前,在各个领域均有学者利用遗传算法进行研究并发表了文章。
例如,文献[10]提出了一种结合多目标优化和精英策略的遗传算法,以对改进的van-Genuchten(VG)模型进行升级,提高了生物炭改良土壤保水模型的预测能力。文献[11]中基于遗传算法设计的自动化方法,能够优化建筑调查激光扫描仪定位网络,最小化点云数据间的重叠。文献[12]将遗传算法用于面部识别领域,并在微表情识别上取得的较好的效果。此外,在能源[13]、医疗[14]、生物信息学[15]等方面,也能发现相关研究,表明遗传算法是一个相当成熟的方法,可以应用于多个方面。然而,遗传算法对适应性度量的定义具有很大的依赖性,不同的适应度定义标准可能会导致最终得到的结果差异巨大。
本文着眼于玉米的转录组测序数据,以挖掘影响玉米百粒重性状的候选基因作为切入点进行研究。挖掘候选基因的过程本质上是特征选择的过程,即从包含全部基因的特征全集中提取部分基因组成一个特征子集,同时保证使用该子集构建的模型相比于使用全集构建的模型具有更出色的性能。通过融合遗传算法与XGBoost,对高质量玉米转录组测序数据及其产量数据进行分析,得到了调控玉米百粒重性状的候选基因。
在模型的准确性方面,将所用模型与分别采用全体基因和差异表达基因(DifferentiallyExpressedGenes,DEGs)进行训练的XGBoost模型进行了比较。此外,传统生信分析往往在获得差异基因后直接进行高层分析,这意味着需要从大量候选基因中进行筛选,任务量繁重而且依赖生物学先验知识。本文方法通过机器学习算法筛选差异基因,有效缩小了候选基因范围,并且不依赖先验知识。
1基因定量和差异表达分析
文章的整体分析方法流程,首先对RNA-Seq数据进行基因定量,根据基因表达量进行差异表达分析。之后,使用GA-XGBoost根据差异基因和表型数据选择基因子集,通过对XGBoost模型中特征重要性排序获得候选基因。最后,对所得候选基因进行功能注释以验证方法有效性。
1.1基因定量
刚脱机的fastq格式转录组测序原始数据中主要包含若干条碱基读段(Read)和其对应的标识信息,开展研究之前,首先需要确定每个读段由哪一个基因转录而来,该基因翻译了几次,这个过程称为基因定量。基因定量主要包括三个步骤。
第一步,质控,对测序数据进行筛选,去除测序样本中长度异常的碱基读段以及样本中的衔接子(adaptor)序列,提高基因定量的准确性。第二步,构建索引,根据参考基因组和其注释文件获得测序物种的外显子和剪切位点信息,构建索引文件,作为碱基序列比对的模板。第三步,定量,通过适当的比对算法,逐一将测序数据中的读段与全部基因比对,确定读段的来源,每次确定读段来源时,其对应的基因表达计数加一。完成基因定量后,每一个样本都会得到一个基因表达矩阵,其中记录了不同基因的表达信息。
一个样本组织中,一定量的RNA中转录本的量是固定的,但使用高通量测序技术对样本进行建库测序时并不能确定一共有多少的转录本,对所测数据进行比对分析所得的基因的表达水平只是相对的定量;此外,基因长度也会影响转录本的读段数量,基因越长,其对应的表达次数往往也就越高。
另一方面,在比较基因在样本间的表达水平时,由于不同样本往往对应不同的测序深度,测序深度更深的样本会得到更多的读段,导致其基因的表达计数更高。因此,在比较不同样本间的基因表达水平之前,需要寻找一种对数据进行标准化处理的方法,消除基因表达定量过程中由于基因长度与测序深度不同而产生的差异。
1.2差异表达分析
一个生物学个体或者组织,在不同的生长发育周期、不同的组织细胞中,其内存在的全体基因并非全部表达,而是根据实际需要部分表达。因此,不同组织或统一组织在不同发育周期中基因的表达模式存在差异,有的基因大量表达行使功能,有的基因少量表达,另一部分基因则完全不表达。往往,具有相同性状的个体或组织间,其基因的表达模式相同,性状相差较大的个体之间,基因的表达模式差别也较大。
基于该情况,在通过测序得到基因的表达信息之后,可以根据样本性状的分组信息,通过统计学方法对其表达模式进行分析,寻找样本间差异表达的基因,进而缩小影响性状的基因范围。差异表达分析的缺陷在于,其分析方法依赖样本的分组信息;另一方面,生物学者进行实验设计时,往往只针对目标性状进行统计,但检测到的差异基因同时包括其他无关性状的相关基因,这也是导致最终得到的差异表达基因较多的原因,需要后续针对目标性状进行深入分析以筛选候选基因。
2基于GA-XGBoost算法的特征选择
2.1XGBoost算法
XGBoost(eXtremeGradientBoosting)是陈天奇于SIGKDD2016大会上提出的一种基于梯度提升和决策树的集成学习方法[20],能够有效地学习数据间的关系。XGBoost使用分类和回归树(ClassificationandRegressionTrees,CART)作为基学习器,通过在损失函数中引入正则项控制模型的复杂度以确保泛化能力,正则项包括叶子节点数和叶子节点权重的平方和。XGBoost的思想是每次增加一棵树拟合上一轮预测结果的残差,通过不断的增加新树达到降低损失值的目的,基于加法模型将多个弱学习器集成为一个强学习器,从而获得一个具有高准确率的机器学习模型。
2.2GA-XGBoost算法
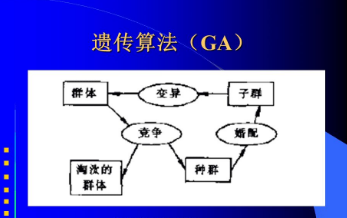
在生物体中,不同的基因负责调控不同的性状,因此,挖掘玉米百粒重性状候选基因的过程本质上是特征选择的过程。将样本包含的全部基因视为特征全集,从中提取部分基因构成一个特征子集,同时保证使用该子集构建的模型相比于使用全集构建的模型具有更出色的性能。遗传算法是模拟生物界种群演化规律的随机搜索算法,主要借鉴种群繁殖过程中个体杂交、染色体交换和基因突变的情况,根据一定的规则模仿自然选择生成新一代种群,并通过不断的重复该过程从而找到最适应环境的最优种群。
在遗传算法中,问题可能的一个解叫做个体,通过一定的编码规则转换为一个唯一的向量表示,称作染色体,一组可能的解构成一个种群。使用遗传算法进行特征选择时,个体适应度的设定对最终所得最优子集具有重要的影响,不够合理的适应度设定将导致最终的子集并非最优解。
本文遗传算法与XGBoost融合,提出遗传算法-极限梯度提升算法(GeneticAlgorithmXGBoost,GA-XGBoost),解决了遗传算法中个体适应性度量的设定问题和XGBoost需要对输入数据进行预处理的问题,并且保留了两个算法各自的优点。基于遗传算法-XGBoost(GA-XGBoost)的特征选择方法包含个体编码、种群初始化、自然选择、染色体交叉和基因突变、迭代结束判断等步骤。
2.3候选基因提取
GA-XGBoost算法结束后,输出最优特征子集信息。该信息是一个编码后的向量,根据2.2介绍的编码方法对该向量进行解码,得到与表型性状相对应的最优基因子集,之后使用该子集中基因的表达量和对应样本的表型数据训练XGBoost模型,根据模型对特征的重要性排序信息,选择排列最靠前的若干基因作为候选基因。
2.4GA-XGBoost时间复杂度分析
使用GA-XGBoost进行数据处理分为遗传算法寻找特征和XGBoost评价个体适应度两部分。遗传算法寻找最优特征时的时间复杂度为
此外,其他常用于特征选择的方法,如基于递归特征消除的支持向量机(SupportVectorMachineRecursiveFeatureElimination,SVM-RFE)[25]算法,SVM模型训练阶段的时间复杂度介于
3实验结果与分析
数据集采用农科院高质量的玉米转录组测序数据和对应的百粒重测产数据。对测序数据进行质控后,比对至玉米B73RefGen_v4参考基因组统计样本中基因的表达水平,并计算FPKM值,对同一实验条件下的重复样品,FPKM取所有重复数据的平均值。
3.1差异表达分析
所用RNA-Seq数据集,经过与参考基因组比对后,共检测到53931个基因,其中表达量不为0的基因个数有41924个。根据样本的分组信息,使用基于R包的Deseq2对表达量非零的基因进行差异表达分析。在校验后P值(P-adjusted,padj)小于0.1的情况下,当|LFC|>0时,共检测到934个基因表达上调,占非0基因总数的2.2%,860个基因表达下调,占非0基因总数的2.1%,共计1794个基因在两组样本间差异表达;当|LFC|>1时,共检测到843个基因表达上调,占非0基因总数的2.0%,699个基因表达下调,占非0基因总数的1.7%,共计1542个基因在两组样本间差异表达。
4结论
在分析了转录组分析方法方面的进展后,本文提出了融合遗传算法与XGBoost的转录组分析方法。以高质量的玉米转录组测序数据和对应的表型数据作为数据集,研究了影响玉米百粒重性状的相关基因。首先分析了遗传算法和XGBoost用于转录组分析领域的可行性,提出了融合遗传算法和XGBoost的方法——GA-XGBoost。在完成转录组数据的预处理工作和差异表达分析之后,使用本文所提方法对其进行了分析,实验得到了48个与玉米百粒重相关的候选基因,并对其进行了基因本体注释和KEGG通路分析。
同时,将本文方法所得模型与分别使用全体基因和差异表达基因进行训练的XGBoost模型进行了比较,在预测结果的准确性上,GA-XGBoost模型具有最低的均方误差,达到3.752,低于使用全体基因的9.183和使用差异表达基因的7.689;在候选基因的范围上,从传统方法直接对1542个差异表达基因进行分析的基础上缩减到验证48个候选基因,表明本文所提方法能够有效提升对转录组数据的分析能力和效率。
本文虽然实现了对于影响玉米百粒重性状的候选基因挖掘,但仍存在不足之处。融合遗传算法和XGBoost的转录组分析方法,虽然能够得到范围更小的候选基因,但是GA-XGBoost算法本身因为使用遗传算法的原因,导致寻找最优子集时可能会消耗较长时间;XGBoost由于具有较多的参数,而使用网格调参时,随着参数的增多计算时间会大幅增加,如何快速且低消耗地寻找到合适参数使得模型达到最优也是值得探讨的问题。此外,通过功能注释虽然能够在一定程度上表明所选基因与百粒重相关,但还需要进一步构建基因调控网络等步骤切实证明所选基因合理可靠,这将是本课题之后的研究方向。
参考文献:
[1]MOROZOVAO,HIRSTM,MARRAMA.ApplicationsofNewSequencingTechnologiesforTranscriptomeAnalysis[J].AnnuRevGenomicsHumGenet,2009,10(1):135-151.
[2]郭茂祖,杨帅,赵玲玲.基于RNA-Seq的转录组分析方法[J].计算机科学,2020,47(S2):35-39.GUOMaozu,YANGShuai,ZHAOLingling.TranscriptomeAnalysisMethodBasedonRNASeq[J].ComputerScience,2020,47(S2):35-39.
[3]KUKURBAKR,MONTGOMERYSB.RNASequencingandAnalysis[J].ColdSpringHarborProtocols,2015,2015(11):951.
[4]XUMaoqiQ,CHENLiang.AnempiricallikelihoodratiotestrobusttoindividualheterogeneityfordifferentialexpressionanalysisofRNA-seq[J].Briefingsinbioinformatics,2018,19(1):109-117.
[5]ZHAOXin,DOUJian,CAOJinglin,etal.UncoveringthepotentialdifferentiallyexpressedmiRNAsasdiagnosticbiomarkersforhepatocellularcarcinomabasedonmachinelearninginTheCancerGenomeAtlasdatabase[J].Oncologyreports,2020,43(6):1771-1784.
作者:杨帅1,2,郭茂祖1,2,赵玲玲3,李阳1,2

转载请注明来自发表学术论文网:http://www.fbxslw.com/jjlw/29145.html